
Zrozumienie mechanizmów działania statusów HTTP pomaga w diagnozowaniu problemów technicznych witryny, optymalizacji crawl budgetu i zapewnieniu, że Google prawidłowo przetwarza strukturę serwisu. Dowiedz się, jak wyszukiwarka traktuje wszystkie klasy kodów: od 200, poprzez 301 i 404, aż do 503.

Czym są statusy HTTP i jak działają
Protokół HTTP (Hypertext Transfer Protocol) to podstawowy protokół komunikacji w internecie, opracowany przez Tima Bernersa-Lee w 1989 roku. Gdy użytkownik lub robot wyszukiwarki próbuje uzyskać dostęp do strony, przeglądarka wysyła żądanie do serwera. W odpowiedzi serwer zwraca nie tylko zawartość strony, ale także kod statusu HTTP wraz z nagłówkami, które informują o wyniku żądania.
Każdy kod statusu HTTP składa się z trzycyfrowej liczby, a jego pierwsza cyfra określa kategorię odpowiedzi. Google Search Central dokumentuje, że w przypadku wyszukiwarki kod statusu 2xx oznacza, że treść otrzymana w odpowiedzi może być rozważana do indeksowania. Z kolei kody z przedziału 4xx-5xx generują komunikaty o błędach w Google Search Console, podobnie jak przekierowania (3xx). Nie oznacza to jednak, że każda informacja o przekierowaniu albo błędzie 4xx w GSC wymaga natychmiastowego działania i jest równoznaczna z poważnymi błędami technicznymi w obrębie strony.
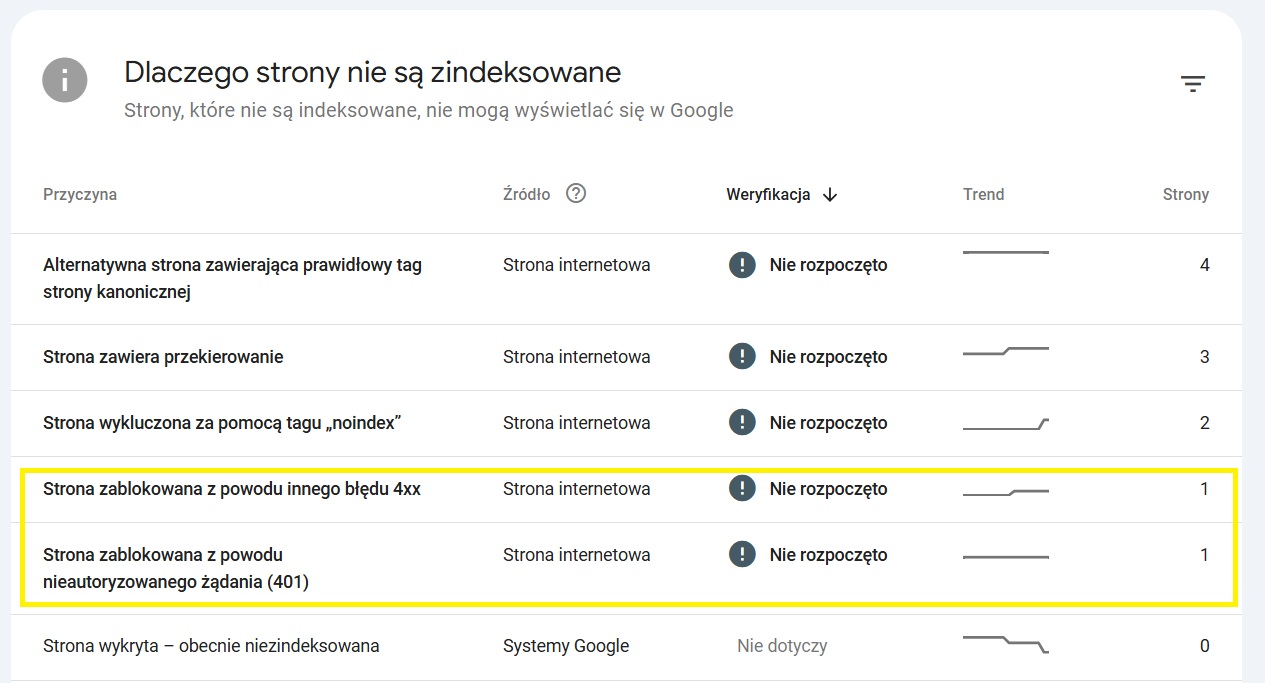
Statusy HTTP są podzielone na pięć głównych kategorii:
1xx (Informacyjne)
Oznaczają, że serwer otrzymał żądanie i pracuje nad jego realizacją, ale proces nie jest jeszcze zakończony. W praktyce SEO te kody są rzadko spotykane. Żeby być stuprocentowo szczerym, przyznać muszę, że dowiedziałem się o ich istnieniu dopiero w trakcie researchu do niniejszego materiału.
2xx (Sukces)
Potwierdzają pomyślne przetworzenie żądania. Najczęściej spotykany jest kod 200 OK, który informuje, że strona jest dostępna i może być zaindeksowana.
| Kod | Nazwa | Jak Google to interpretuje |
|---|---|---|
| 200 | success | Google przekazuje odebraną treść do kolejnego etapu przetwarzania (zależnego od produktu). W przypadku Google Search kolejnym systemem jest pipeline indeksowania. Treść może zostać zindeksowana, ale nie jest to gwarantowane. |
| 201 | created | Dla robotów Google traktowane zasadniczo jak 200: treść jest przekazywana dalej do pipeline’u indeksowania i może zostać zindeksowana, choć nie ma takiej gwarancji. |
| 202 | accepted | Google czeka przez ograniczony czas na treść, a następnie przekazuje to, co udało się odebrać, do kolejnego etapu przetwarzania. Limit czasu zależy od user-agenta. np. Googlebot Smartphone może mieć inny timeout niż Googlebot Image. |
| 204 | no content | Google nie jest w stanie odebrać żadnej treści z danego URL, więc nie może jej przetworzyć ani wykorzystać do indeksowania. |
3xx (Przekierowania)
Wskazują, że zasób został przeniesiony w inne miejsce. Przeglądarka lub bot automatycznie podąża za wskazaną lokalizacją. W tej kategorii znajdują się kluczowe dla SEO kody 301 (przekierowanie stałe) i 302 (przekierowanie tymczasowe).
| Kod | Nazwa | Jak Google to interpretuje |
|---|---|---|
| 301 | moved permanently | Google podąża za przekierowaniem, a systemy Google traktują je jako silny sygnał, że docelowy adres URL powinien być przetwarzany (i w praktyce zwykle indeksowany zamiast starego). |
| 302 | found | Domyślnie roboty Google podążają za przekierowaniem, ale systemy Google traktują je jako słabszy, tymczasowy sygnał niż 301. Docelowy URL może być przetwarzany, ale przekaz o trwałej zmianie jest słabszy. Inne produkty Google mogą obsługiwać ten kod inaczej. |
| 303 | see other | Dla Google w kontekście wyszukiwarki działa podobnie jak inne przekierowania tymczasowe (zbliżone do 302) – robot podąża za przekierowaniem, ale nie jest to silny sygnał trwałej zmiany. |
| 304 | not modified | Roboty Google sygnalizują kolejnemu systemowi, że treść strony nie zmieniła się od ostatniego crawlowania. W Google Search pipeline indeksowania może jedynie przeliczyć sygnały dla URL, ale sam kod 304 nie zmienia statusu indeksowania. |
| 307 | temporary redirect | W praktyce traktowane jak 302: Google podąża za przekierowaniem, ale jest to sygnał tymczasowej zmiany i słabszy niż 301. |
| 308 | moved permanently | W praktyce traktowane jak 301: Google podąża za przekierowaniem i interpretuje je jako silny sygnał trwałego przeniesienia treści na docelowy URL. |
4xx (Błędy klienta)
Sygnalizują problem po stronie żądania. Najczęstszy jest kod 404 (strona nie znaleziona), który pojawia się, gdy żądany zasób nie istnieje. Jak podkreślało Google na swoim blogu jeszcze w czasach SEO łupanego, błędy 404 są normalną częścią internetu i nie szkodzą SEO pozostałych stron serwisu.
| Kod | Nazwa | Jak Google to interpretuje |
|---|---|---|
| 400 | bad request | Wszystkie błędy z zakresu 4xx (poza 429) są traktowane podobnie: roboty Google przekazują do kolejnego systemu informację, że treść pod tym adresem nie istnieje lub jest niedostępna. Z czasem częstotliwość crawlowania takiego URL spada. |
| 401 | unauthorized | Strona wymaga autoryzacji – Google nie ma dostępu do treści. W przypadku Google Search adres URL może zostać usunięty z indeksu, jeśli wcześniej był zindeksowany. Sam kod (jak inne 4xx oprócz 429) nie służy do sterowania crawl rate. |
| 403 | forbidden | Dostęp zabroniony – robot Google nie może pobrać treści. Dla wyszukiwarki działa to jak inne błędy 4xx: stary, zindeksowany URL może zostać usunięty, a częstotliwość crawlowania stopniowo maleje. Google nie zaleca używania 403 do ograniczania crawl rate. |
| 404 | not found | Strona nie istnieje. Nowo napotkane 404 nie są dalej przetwarzane, a wcześniej zindeksowane adresy z czasem wypadają z indeksu. Kod 404 sam w sobie nie wpływa na ogólny crawl rate domeny. |
| 410 | gone | Treść została trwale usunięta. Ogółem jest to silniejszy sygnał trwałego zniknięcia niż 404, chociaż dla Google nie ma to większej róznicy, ponieważ nadal należy do grupy 4xx – URL jest traktowany jako nieistniejący i z czasem usuwany z indeksu. |
| 411 | length required | Żądanie nie zawiera wymaganej informacji o długości. W praktyce dla Google zachowuje się jak inne błędy 4xx: treść nie jest wykorzystywana, a adres może być traktowany jak nieistniejący. |
| 429 | too many requests | Roboty Google interpretują 429 jako sygnał, że serwer jest przeciążony lub ogranicza liczbę żądań. Kod ten traktowany jest podobnie jak błąd serwera (5xx) i może prowadzić do tymczasowego zmniejszenia tempa crawlowania. Różni się więc od innych błędów 4xx. |
5xx (Błędy serwera)
Oznaczają, że serwer napotkał problem i nie może zrealizować żądania. Najbardziej powszechne to 500 (wewnętrzny błąd serwera) i 503 (usługa niedostępna). Te kody mają istotny wpływ na crawling, ponieważ według dokumentacji Google poświęconej crawlowaniu, gdy Googlebot napotyka znaczną liczbę odpowiedzi 500, 503 lub 429, automatycznie redukuje częstotliwość crawlowania całej domeny.
| Kod | Nazwa | Jak Google to interpretuje |
|---|---|---|
| 500 | internal server error | Błąd po stronie serwera. Google obniża tempo crawlowania dla witryny; skala obniżki zależy od liczby adresów, które zwracają błąd. W Google Search adresy, które przez dłuższy czas konsekwentnie zwracają 500, mogą zostać usunięte z indeksu. |
| 502 | bad gateway | Traktowane jak błąd 500 – problem po stronie serwera/pośrednika. Google tymczasowo zmniejsza crawl rate i ignoruje treść z odpowiedzi, dopóki błędy się utrzymują. |
| 503 | service unavailable | Serwis tymczasowo niedostępny. Dla Google to również błąd serwera z grupy 5xx: roboty spowalniają crawlowanie, a treść z odpowiedzi nie jest używana. Przy dłuższym utrzymywaniu się błędów adresy mogą stopniowo wypadać z indeksu. |
Oficjalne stanowisko Google wobec statusów HTTP
Google wielokrotnie wypowiadało się na temat obsługi poszczególnych kodów statusu. Niezwykle istotne dla technicznego SEO informacje pochodzą z oficjalnej dokumentacji oraz wypowiedzi przedstawicieli firmy.
Przekierowania 301 vs 302
Jedna z najczęstszych kwestii w SEO dotyczy różnic między przekierowaniami 301 (stałe) a 302 (tymczasowe). Długo panowało przekonanie, że 302 przekazują mniejszą wartość „link juice” niż 301. Jednak John Mueller wielokrotnie potwierdzał, że z perspektywy SEO wszystkie typy przekierowań są traktowane podobnie. W 2016 roku napisał: „Either the search engine indexes the content with its signals under R or under S, it doesn’t matter which type of redirect you use.”
Różnica polega głównie na intencji i cacheowaniu. Według dokumentacji Google, przekierowanie 301 informuje Googlebot, że strona została przeniesiona na stałe i wszystkie odniesienia do starego URL powinny zostać zaktualizowane. Z kolei 302 sugeruje, że zmiana jest tymczasowa i oryginalny URL może powrócić. Mueller rekomenduje utrzymywanie przekierowań 301 przez co najmniej rok, aby dać wyszukiwarkom czas na pełne przeniesienie sygnałów rankingowych.
Znacznie istotniejsze w kontekście przekierowań 301 wydaje się minimalizowanie tzw. łańcuchów przekierowań, czyli sytuacji, w których 301 prowadzą do 301 prowadzących do kolejnych 301. Jak podkreślał Mueller w podlinkowanym powyżej wpisie ze swojego bloga, Google śledzi do 5 przekierowań w jednym łańcuchu. Obecnie w dokumentacji widnieje liczba 10 przekierowań na łańcuch i to ją uznać trzeba raczej za aktualną.
Bardzo ciekawy status 304
Ze statusem 304 spotkałem się w praktyce po raz pierwszy w ciągu ostatniego roku. Jest on interesujący o tyle, że w przeciwieństwie do 301 czy 302 nie daje informacji o przekierowaniu, lecz sygnalizuje crawlerowi status cache’owania. Gdy Googlebot otrzymuje 304 Not Modified, oznacza to po prostu, że treść nie zmieniła się od ostatniego pobrania i nie musi ponownie pobierać jej zawartości.
Gary Illyes opublikował jednak na Linkedinie bardzo ciekawy teoretyczny case, w którym serwowanie googlebotowi stron 304 może być strzałem w stopę. Kiedy taki status staje się problemem?
- Crawler wchodzi pod URL.
- Serwer ma błąd, ale zwraca 200 OK — strona jest pusta lub uszkodzona.
- Crawler uznaje to za soft-404 i planuje ponowne sprawdzenie.
- Przy kolejnym wejściu serwer zwraca 304 Not Modified (bo „nic się nie zmieniło”).
- Crawler „uczy się”, że błąd jest trwały i przestaje wracać pod takie adresy (aktualizacja strony może wisieć w próżni przez długi czas).
Błędy 404 i 410
Kolejny często dyskutowany temat to różnica między kodami 404 (nie znaleziono) a 410 (trwale usunięte). W kwietniu 2024 roku John Mueller rozstrzygnął tę kwestię w komentarzu z Reddita opisanym szerzej w artykule z Search Engine Journal: „It doesn’t matter. The difference in processing of 404 vs 410 is so minimal that I can’t think of any time I’d prefer one over the other for SEO purposes.”
Mueller przyznał, że teoretycznie 410 może być szybciej usunięty z indeksu o dzień lub dwa, ale w praktyce różnica jest na tyle niewielka, że nie ma znaczenia dla SEO. Oba kody powodują, że strony są usuwane z indeksu i Google redukuje ich crawlowanie, aby nie marnować zasobów. Jak potwierdza oficjalna dokumentacja, błędy 404 nie mają negatywnego wpływu na rankingi innych stron w witrynie i można je bezpiecznie ignorować, jeśli jesteśmy pewni, że dane URL nie powinny istnieć.
Problematyka soft 404
Soft 404 to sytuacja, w której serwer zwraca kod 200 (sukces) dla strony, która w rzeczywistości nie istnieje lub ma bardzo mało treści. Google od dawien dawna zdecydowanie odradza takie praktyki, ponieważ wprowadzają w błąd zarówno użytkowników, jak i wyszukiwarki. Zamiast zwracać 200 mimo braku treści, serwer powinien odpowiadać właściwym kodem 404 lub 410.
Jak wyjaśniał Gary Illyes w prezentacji opisanej przez Kenichiego Suzuki, soft 404 zużywają crawl budget mimo zwracania statusu 200. To główna różnica pomiędzy nimi, a standardowymi 404, która czyni z soft 404 błąd krytyczny! Google używa analizy treści do wykrywania tego typu niespójności i jeśli wykryje wzorce wskazujące na brakującą lub bezwartościową stronę, oznaczy URL jako soft 404, nawet gdy kod HTTP sugeruje, że strona jest dostępna.
Błędy serwera 5xx
Statusy z zakresu 5xx mają znaczący wpływ na crawling. Według Gary’ego Illyesa, serwowanie kodu 503 (usługa niedostępna) przez dłuższy czas spowoduje spadek częstotliwości crawlowania. Krótkie przestoje z kodem 503 są akceptowalne – Google rozumie, że witryny wymagają okresowych przerw konserwacyjnych. Problem pojawia się, gdy błędy 5xx utrzymują się przez wiele dni – wtedy Google może zacząć zakładać, że serwis został całkowicie wyłączony i zacznie usuwać strony z indeksu.
W przypadku planowanych przerw konserwacyjnych, najlepsza praktyka to zwracanie kodu 503 z nagłówkiem Retry-After, choć Google nie zawsze przestrzega wartości tego nagłówka, gdyż wiele witryn używa go w sposób ogólny. Ważne jest, aby w przypadku tymczasowych problemów serwer zwracał 503, a nie 404 – jeśli Googlebot napotka 404 podczas awarii, może potraktować to jako permanentne usunięcie strony i szybko wyrzucić ją z indeksu.
W ten sposób używamy statusów HTTP w SEO
Kody sukcesu 2xx
Kod 200 OK to standardowa odpowiedź dla prawidłowo działającej strony. Każda strona, którą chcemy, aby Google zaindeksował, powinna zwracać ten status. Warto jednak pamiętać, że sam kod 200 nie gwarantuje indeksowania – Google może zdecydować, że strona nie powinna trafić do indeksu z innych powodów (np. duplikat nieposiadający canonical tag, thin content czy niska jakość wykluczająca sens zindeksowania).
Przekierowania 3xx
301 Moved Permanently to najbardziej powszechne przekierowanie w SEO. Używamy go gdy:
- zmieniamy strukturę URL na stałe,
- migrujemy witrynę do nowej domeny,
- konsolidujemy treści (łączymy kilka stron w jedną),
- przechodzimy z wersji bez www na wersję z www i vice versa.
Google zaleca, aby unikać łańcuchów przekierowań (redirect chains). Zamiast tworzyć ciąg A → B → C, lepiej skonfigurować bezpośrednie przekierowanie A → C. Jak zostało już wspomniane, Googlebot podąża maksymalnie za 10 przekierowaniami w łańcuchu, więc dłuższe ciągi mogą uniemożliwić indeksowanie strony docelowej.
302 Found używamy dla zmian tymczasowych:
- testy A/B (choć Google zaleca używanie JavaScript),
- tymczasowe prace konserwacyjne,
- przekierowania zależne od lokalizacji użytkownika lub urządzenia.
Jeśli przekierowanie 302 pozostaje aktywne przez długi czas, Google może zacząć traktować je jak 301, co spowoduje przeniesienie sygnałów rankingowych do URL docelowego. Prawdę mówiąc, w praktyce nie spotkałem się z sensownym wykorzystaniem 302.
307 Temporary Redirect i 308 Permanent Redirect to nowsze wersje odpowiednio 302 i 301, wprowadzone w HTTP/1.1. Główna różnica polega na tym, że wymagają one zachowania oryginalnej metody HTTP (GET, POST) przy przekierowaniu. Google deklaruje w dokumentacji, że traktuje je dokładnie tak samo:
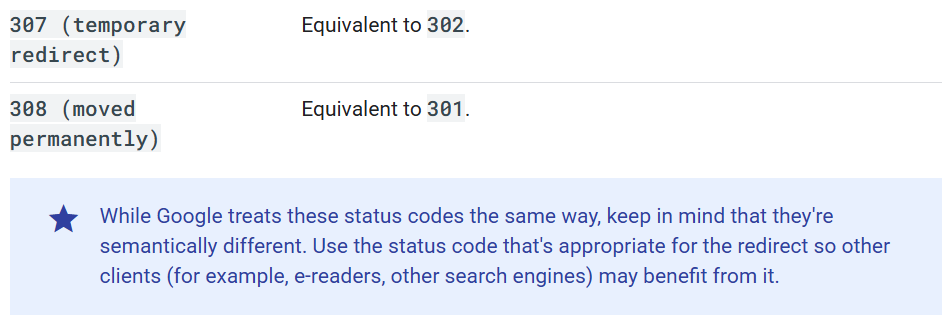
Błędy klienta 4xx
404 Not Found to naturalny kod dla nieistniejących stron. Obecność błędów 404 w witrynie nie ma negatywnego wpływu na ranking pozostałych podstron z witryny ani na ocenę całej domeny. Wręcz przeciwnie – Google woli widzieć prawidłowe 404 niż soft 404. Doskonały materiał na temat tego, czy 404 są szkodliwe dla SEO, przygotowała przed kilkoma laty Olga Zarr.
Dobrą praktyką jest tworzenie przyjaznych stron 404, które:
- jasno informują użytkownika, że strona nie istnieje,
- oferują przydatne linki do popularnych sekcji serwisu,
- zawierają wyszukiwarkę wewnętrzną,
- zachowują spójny design z resztą witryny.
Sprawdź przykłady podstron 404, które naprawdę przyjemnie się ogląda i natrafienie na nie wywołuje albo zaciekawienie, albo uśmiech. W tym pierwszym przypadku chęć dalszej eksploracji strony jest czasami nieodparta, a w tym drugim… Cóż, uśmiechanie się jest zdrowe i przyjemne.
Błąd 410 Gone stosujemy, gdy chcemy wyraźnie zaznaczyć, że strona została permanentnie usunięta i nigdy nie powróci. W praktyce różnica między 404 a 410 jest minimalna, więc można używać dowolnego z nich.
Błędy serwera 5xx
500 Internal Server Error to ogólny komunikat o problemie po stronie serwera. Warto śledzić w logach serwera, jak często tego typu błędy się pojawiają, a także czy dotyczą konkretnego typu podstron. Pozwala to wykryć niechciane problemy z serwowaniem konkretnych treści oraz dostępem bota Google’a do nich.
503 Service Unavailable to natomiast preferowany kod dla planowanych przerw konserwacyjnych. Informuje on Google, że problem jest tymczasowy i powinien ponownie sprawdzić stronę później. Gary Illyes potwierdza, że krótkie przestoje z kodem 503 są akceptowalne, ale długotrwałe serwowanie 503 spowoduje spadek częstotliwości crawlowania.
Typowe błędy i mityczne przekonania
Mit: „Należy używać 410 zamiast 404 dla usuniętych stron”
Choć technicznie 410 jest bardziej precyzyjny dla permanentnie usuniętych zasobów, John Mueller jasno stwierdza, że różnica w przetwarzaniu tych kodów jest „so minimal that I can’t think of any time I’d prefer one over the other for SEO purposes”. Oba kody powodują usunięcie strony z indeksu w podobnym czasie.
Mit: „Błędy 404 szkodzą SEO całej witryny”
To nieprawda. Google oficjalnie komunikuje, że błędy 404 są normalną częścią internetu i nie wpływają na rankingi pozostałych stron. Problem pojawia się tylko wtedy, gdy 404 dotyczą ważnych stron z wartościowymi linkami zwrotnymi – wtedy tracimy potencjał rankingowy, który te linki mogłyby przekazać. Jeżeli mamy fajne backlinki do konkretnych podstron, dobrze utrzymywać je w zdrowiu lub przekierować 301 na treść o podobnej tematyce.
Mit: „Przekierowanie wszystkiego do strony głównej to dobra praktyka”
Niektórzy webmasterzy, chcąc uniknąć błędów 404, przekierowują wszystkie nieistniejące URL na stronę główną. Jeśli strona nie ma naturalnego następcy pod 301, lepiej zwrócić prawidłowy błąd 404, niż kierować użytkowników do strony głównej lub strony kategorii. Co więcej, z jednej z wypowiedzi Johna Muellera na Reddicie wynika, iż w dłuższej perspektywie czasowej takie adresy mogą być traktowane przez systemy Google’a jako soft-404:
Category redirect: URL doesn’t get indexed. Potentially a short-term support for the category page, but still confusing to users. (If you do this, at least display something on the page explaining how they got there.) Longer-term soft-404.
Mit: „Soft 404 to nieistotny szczegół”
Soft 404 są często pomijanym problemem, chociaż zgodnie z podlinkowywanym ją wypowiedziom traktowane są przez Google jako błąd krytyczny”. Najczęstsze przyczyny soft 404 to:
- thin content (strony z minimalną ilością contentu),
- puste lub duplikujące się strony wyników wewnętrznego wyszukiwania
- strony produktów „out of stock” bez właściwej obsługi,
- przekierowania usuniętych stron na nieistotne URL,
- strony z dominującym komunikatem „nie znaleziono” zwracające 200 zamiast 404.
Rozwiązanie polega na zwracaniu właściwego kodu 404 lub 410, ewentualnie wdrożeniu przekierowania 301 do istotnej alternatywnej treści.
Skąd wiedzieć, jakie statusy HTTP widzi googlebot?
Istnieje kilka sposobów na weryfikację tego, na co natyka się googlebot podczas odwiedzin naszej strony. Należą do nich:
- Logi serwera – analiza logów pozwala zobaczyć, jakie kody statusu faktycznie zwracał serwer dla Googlebota. To kluczowe, bo czasem różne narzędzia widzą różne odpowiedzi ze względu na konfigurację user-agent czy CDN. Jednocześnie logi serwera są jedynym stuprocentowo pewnym źródłem wiedzy.
- Google Search Console – drugie pod kątem wagi źródło informacji o tym, jak Google widzi statusy HTTP Twojej witryny. Raport „Indeksowanie stron” pokazuje problemy z crawlingiem, w tym błędy 4xx, 5xx i soft 404.
- Screaming Frog – narzędzie do crawlowania witryny, które raportuje wszystkie napotkane statusy HTTP. Umożliwia masową analizę redirectów, łańcuchów przekierowań oraz broken links. Szczególnie przydatne do identyfikowania problemów przed migracją witryny i chwilę po niej.
Podsumowanie
Statusy HTTP stanowią fundamentalny mechanizm komunikacji między serwerem a wyszukiwarkami. Prawidłowa konfiguracja kodów statusu zapewnia, że Google efektywnie crawluje i indeksuje wartościowe treści, nie marnując zasobów na strony nieistotne lub nieistniejące.
Najważniejsze wnioski:
- Używaj 301 dla stałych zmian URL, 302 dla tymczasowych.
- Błędy 404 są naturalne i nie szkodzą SEO pozostałych stron.
- Różnica między 404 a 410 jest minimalna dla SEO.
- Unikaj soft 404 – zawsze zwracaj właściwy kod statusu.
- Błędy 5xx mają natychmiastowy wpływ na crawling i mogą szkodzić SEO.
- Regularnie monitoruj statusy HTTP w logach serwera oraz w Google Search Console.
Pamiętaj, że statusy HTTP to tylko jeden z wielu elementów technicznego SEO, ale ich niewłaściwe użycie może uniemożliwić Google dostęp do Twoich treści. Warto inwestować czas w ich prawidłową konfigurację i regularne sprawdzanie, czy wszystko jest z nimi okej.
Te artykuły powinny Cię zainteresować
O autorze
Nazywam się Michał Małysa i od wielu lat zajmuję się zawodowo SEO oraz analizą treści, a od 2023 roku w zakres moich obowiązków i zainteresowań dość naturalnie weszło AI. Na stronie MałySEO porządkuję wiedzę o pozycjonowaniu stron internetowych, AI Search oraz działaniu LLM-ów. Prowadzę również MałySEO Newsletter, do którego subskrypcji serdecznie Cię zachęcam na podstronie najlepszego w Polsce newslettera SEO.
Jako że przygotowanie materiałów do MałySEO Newslettera oraz na bloga zajmuje nieco czasu, może zaświtać Ci w głowie dość miły z mojej perspektywy pomysł drobnego rewanżu. Jeżeli uznasz, że lektura tego wpisu była dla Ciebie czymś więcej, niż tylko szybkim odklepaniem randomowej internetowej treści, możesz postawić mi kawkę na buycoffee.to. Z góry dziękuję!

Jeżeli z jakiegoś powodu potrzebujesz się ze mną skontaktować, wyślij mail na adres kontakt[at]michalmalysa.pl