
W niniejszym poradniku nie tylko pokazuję, jak krok po kroku połączyć się z API Claude AI przy pomocy Pythona, ale wyjaśniam również, jak efektywnie korzystać z modeli stworzonych przez Anthropic za pośrednictwem API, jakie opcje mamy do wyboru, ile to kosztuje, jak wygląda struktura zapytań i odpowiedzi oraz jakie zaawansowane funkcje warto znać.

Pierwotna wersja tekstu powstała w lipcu 2024 roku, gdy Claude API było dopiero ciekawostką i nie cieszyło się tak dużą popularnością jak modele od OpenAI oraz Google. W lutym 2026 roku, gdy Claude jest dla wielu zastosowań docelowym narzędziem AI, artykuł przeszedł gruntowną metamorfozę w celu aktualizacji wiedzy.
Dostępne modele Claude przez API
API Claude AI daje dostęp do kilku modeli, które różnią się ceną, szybkością i możliwościami. Wybór modelu to podstawowe ustawienie każdego zapytania do API. Wpisujesz konkretny identyfikator modelu (tzw. model string) w parametr model i to on determinuje, co dostaniesz w odpowiedzi i ile za to zapłacisz.
Na dzień pisania tego poradnika najważniejsze modele to:
| Model | Identyfikator (model string) | Charakterystyka | Context window |
| Claude Opus 4.6 | claude-opus-4-6 | Najinteligentniejszy model, najlepszy w złożonych zadaniach analitycznych i kreatywnych, idealny do kodowania i tworzenia rozwiązań agentowych. | 200k tokenów |
| Claude Sonnet 4.5 | claude-sonnet-4-5-20250929 | Zbalansowany model. Mocny, szybki i znacznie tańszy od Opusa, a przy tym w większości zastosowań jak najbardziej wystarczający. | 200k tokenów |
| Claude Haiku 4.5 | claude-haiku-4-5-20251001 | Najszybszy i najtańszy, idealny do prostych zadań na dużą skalę. A przynajmniej tak twierdzi Anthropic, ponieważ sam nie miałem z tym modelem do czynienia. | 200k tokenów |
Context window (okno kontekstowe) to ważny parametr, który określa, ile tekstu model przyjmie w ramach jednego zapytania. 200K tokenów to w uproszczeniu około 150 000 słów, więc mieści się tam nawet średniej grubości książka. Po wdrożeniu w lutym 2026 roku modelu Claude Opus 4.6, Anthropic zaczął również dopuszczać w ramach betatestów znacznie większe zapytania, sięgające nawet 1 mln tokenów. Obecnie są one dostępne również dla modelu Sonnet 4.5, jednak input jest wówczas dwukrotnie droższy, natomiast output x1,5.
- Do większości zastosowań wystarcza Sonnet 4.5, który oferuje najlepszy stosunek jakości do ceny.
- Wyższy model warto rozważyć przy dopiero naprawdę złożonych zadaniach (np. analiza dużych dokumentów, zaawansowane rozumowanie). Sam korzystam z Opus 4.6 do generowania treści, a w trybie Extended Thinking przy vibe-codowaniu przez Claude Code oraz w webowym Claude AI.
- Haiku sprawdzi się tam, gdzie liczy się szybkość i koszt, a jakość nie musi być absolutnie topowa. W tym ostatnim przypadku sam wybieram jednak Gemini Flash 2.5, ponieważ oferuje wystarczającą jakość przy niższych kosztach.
Aktualna lista dostępnych modeli oraz ich identyfikatory dostępna jest zawsze w oficjalnej dokumentacji Anthropic. Powyższa tabela ma w sumie charakter mocno poglądowy, ponieważ różnego rodzaju parametry zapytań do API potrafią zmieniać się z miesiąca na miesiąc, więc bardzo możliwe, że kilka tygodni po uzupełnieniu artykułu będzie on w kwestii tych szczegółów nieaktualny.
Jak uzyskać klucz API Claude AI?
Klucz API to unikalny ciąg znaków, który uwierzytelnia zapytania do serwera Anthropic. Bez niego API nie przyjmie żadnego żądania. Klucz generujesz i zarządzasz nim w Anthropic Console. To panel webowy, w którym poza kluczami obsługujesz również dostępne środki czy monitorujesz zużycie.
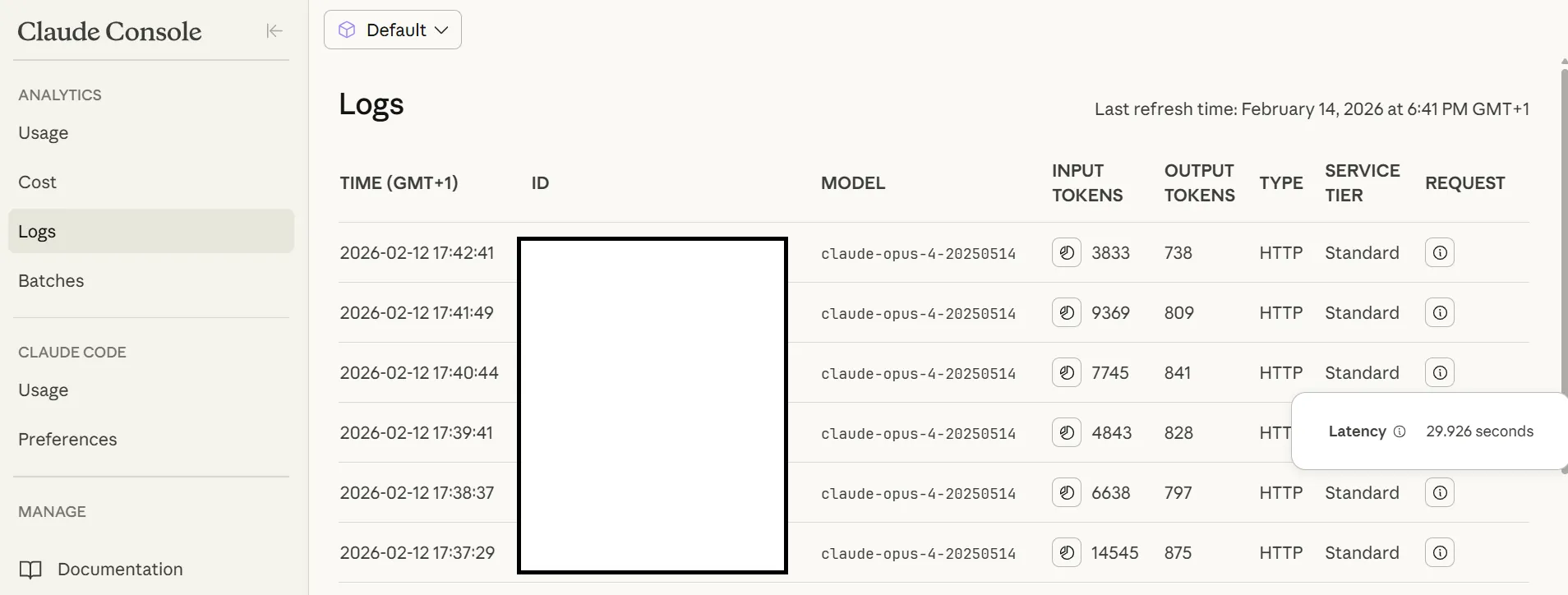
Aby uzyskać klucz API, należy:
- Wejść do konsoli Anthropic.
- Zalogować się przy pomocy konta Google lub założyć konto bezpośrednio.
- Niezależnie od wybranej opcji przejść proces weryfikacji przez SMS.
- W menu po lewej stronie wybrać jedną z trzech opcji API Keys/Limits/Settings.
- W dodatkowym menu, które się wyświetli, kliknąć zakładkę „Billing”.
- Doładować konto za minimum 5$ (do kwoty zostanie doliczony VAT, więc przy doładowaniu za 10$ zapłacimy 12,3$).
- Po doładowaniu konta wybrać zakładkę „API Keys”.
- Kliknąć czarny button „Create Key”.
- Po wybraniu nazwy wygenerować klucz API i zapisać go w bezpiecznym miejscu.
Ważna uwaga o bezpieczeństwie: klucz API traktuj jak hasło, którego ujawnienie może pozbawić Cię pieniędzy. Nie wrzucaj go do publicznych repozytoriów, nie wklejaj w otwarte pliki. Każda osoba, która zna Twój klucz, może korzystać z API na Twój koszt. Przy bardziej zaawansowanych projektach dobrą praktyką jest przechowywanie klucza w dedykowanym pliku .env, a nie bezpośrednio w kodzie Python.
Jak płaci się za API Claude i ile to kosztuje?
Podobnie jak w przypadku wielu innych narzędzi AI, tokeny to podstawowa jednostka rozliczeniowa API Claude. Każde zapytanie generuje dwa rodzaje tokenów:
- Input tokens, wysyłane w zapytaniu (prompt, system prompt, kontekst).
- Output tokens, generowane przez model w odpowiedzi.
Jeden token to mniej więcej 3/4 słowa w języku angielskim (w polskim nieco mniej, bo nasze słowa bywają dłuższe). Zdanie „Ala ma kota” to w zależności od tokenizera około 4–5 tokenów.
Cennik podawany jest w dolarach za milion tokenów i różni się w zależności od modelu. Przytaczanie dokładnych kwot nie ma sensu, bo wraz z premierami kolejnych modeli ceny się zmieniają. Aktualny cennik znajdziesz zawsze w podlinkowywanej już dokumentacji na stronie Anthropic.
API Claude AI działa w modelu prepaid, czyli nie pobiera opłat z karty na bieżąco, tylko wymaga wcześniejszego doładowania konta kredytami. Oczywiście dostępna jest opcja automatycznego uzupełniania bilansu, kiedy schodzi do zera, a firmy mogą skontaktować się z przedstawicielami Anthropic w celu negocjacji miesięcznego fakturowania w modelu „pay after-the-fact”.
Przykładowe koszty generowania treści z Claude API
A ile kosztuje korzystanie z API Claude w praktyce? Przygotowanie wpisów z bloga stanowiących follow-up do MałySEO Newslettera (skróty najważniejszych newsów o AI oraz podsumowania do repozytorium badań i statystyk SEO) przy pomocy modelu Opus 4.6 wygenerowało w ostatnich dwóch tygodniach następujące koszty:
- 12 lutego 2026 roku 2,62$ za 17 wpisów (110k tokenów inputu przy 12k tokenach outputu),
- 5 lutego 2026 roku 4,81$ za 25 wpisów (228k tokenów inputu przy 18k tokenach outputu).
Krok 1: Formułujemy proste zapytanie do Claude API
Standardowo dla moich poradników skorzystamy z Pythona w obrębie Google Colab. Jeżeli nie chcesz budować zapytań od podstaw, możesz skorzystać z gotowych punktów przygotowanego przeze mnie skryptu. Zachęcam jednak do prostego formułowania swoich potrzeb bezpośrednio w Colabie albo w innym systemie ułatwiającym vibe coding (na co dzień korzystam z Anitgravity, ponieważ obecnie wolę odpalać skrypty z dysku + Gemini Flash 2.5 w obrębie darmowego Colaba to jednak dramat jest). Właśnie tak powstawały kolejne kroki:
Zanim jednak odpalę skrypt, kilka słów o tym, jak technicznie wygląda komunikacja z API Claude AI. Pod spodem mamy do czynienia z klasycznym REST API. Wysyłamy zapytanie HTTP (konkretnie POST) na adres URL endpointu, a w odpowiedzi dostajemy dane w formacie JSON. Główny endpoint API Claude to:
https://api.anthropic.com/v1/messages
Nie trzeba jednak składać zapytań HTTP ręcznie. Anthropic udostępnia oficjalny Python SDK (bibliotekę anthropic), która ułatwia komunikację z Claude API. Wystarczy zainstalować go komendą pip install anthropic(w przypadku Colaba dodajemy przed komendą pip wykrzyknik).
Aby sformułować zapytanie do Claude API, należy:
- wskazać klucz API
- określić wiadomość wysyłaną do API (
user_message), - określić wiadomość systemową (
system_message), - wskazać tryb odpowiedzi (podstawowy to
client.messages.create), - wybrać model (
model), - określić maksymalną liczbę tokenów w odpowiedzi (
max_tokens), - ustawić temperaturę odpowiedzi (
temperature), - wskazać rolę (
role) jako user oraz zawartość (content) określoną wcześniej wuser_message - określić formę przetwarzania odpowiedzi (przy prostym zapytaniu będzie to po prostu wydruk w konsoli, czyli
print, wraz ze wskazaniem do wydruku elementutext).
Co musisz wiedzieć na temat tych parametrów, jeśli nie miałeś wcześniej do czynienia z korzystaniem z API jakiegokolwiek modelu AI?
Parametry zapytania
Podstawowe parametry, które wysyłasz w body zapytania (request body) w formacie JSON:
| Parametr | Opis | Przykładowa wartość |
model |
Identyfikator modelu, który ma obsłużyć zapytanie | "claude-sonnet-4-5-20250929" |
max_tokens |
Maksymalna liczba tokenów, jaką model może wygenerować w odpowiedzi | 4096 |
messages |
Lista wiadomości – tu trafia Twój prompt | [{"role": "user", "content": "Napisz..."}] |
system |
System prompt – nadrzędna instrukcja kontrolująca zachowanie modelu | "Jesteś ekspertem SEO..." |
temperature |
Reguluje losowość/kreatywność odpowiedzi (0.0–1.0) | 0.7 |
Temperatura czy maksymalna liczba tokenów to wartości, które nie są obowiązkowe, ale jako że wszystkie LLM-y wrzucają je do generowanych zapytań w Pythonie, nic nie zaszkodzi dokładniejsze ich poznanie.
System prompt, czyli kontrola zachowania modelu
System prompt to instrukcja, którą przekazujesz modelowi ponad samym promptem użytkownika. Zazwyczaj definiuje on rolę, styl i ograniczenia, w ramach których model generuje odpowiedź. To proste jak drut polecenie, z którego warto korzystać, bo nawet mocno ograniczony system prompt potrafi diametralnie zmienić jakość outputu.
Temperature, czyli losowość odpowiedzi
Parametr temperature kontroluje, jak kreatywny (albo jak losowy) będzie model. Wartość 0.0 oznacza maksymalną przewidywalność, czyli model za każdym razem wybierze najbardziej prawdopodobny token (choć nie ma pewności, że będą one deterministyczne). Wartość 1.0 to większa losowość i kreatywność, ale też wyższe ryzyko halucynacji. Oczywiście znajdziecie szamanów prompt engeneeringu, którzy mają jedyne słuszne formuły na temperaturę, ale to raczej parametr stosowany na wyczucie.
max_tokens ogranicza długość odpowiedzi
Przy zastosowaniach produkcyjnych ustawia się często parametr max_tokens, aby określić maksymalną liczbę tokenów w odpowiedzi modelu. Jeśli ustawisz za mało, tekst zostanie ucięty w połowie zdania. Jeśli ustawisz za dużo, nic złego się nie stanie, model po prostu zakończy odpowiedź naturalnie.
Jeżeli już zdecydujemy się z niego skorzystać, warto ustawiać ten parametr z pewnym zapasem względem oczekiwanej długości tekstu (i brać pod uwagę <thinking> output przy modelach reasoningowych) i szczególnie uważać na niego przy generowaniu zapytań do API przez chatboty AI. Tak tworzone requesty mają tendencję do ustawiania dość niskiej maksymalnej liczby tokenów.
Struktura odpowiedzi
API Claude zwraca odpowiedź w formacie JSON. Kluczowy element to tablica content, w której znajdziesz wygenerowany tekst:
{
"content": [
{
"type": "text",
"text": "Tu jest wygenerowana treść..."
}
],
"model": "claude-sonnet-4-5-20250929",
"usage": {
"input_tokens": 523,
"output_tokens": 1847
}
}Obiekt usage jest szczególnie przydatny, bo zawiera informację o zużytych tokenach. Dzięki niemu możesz monitorować koszty oraz optymalizować większe tokenożerne projekty. Przy testowaniu nie ma to często znaczenia, ale w dłuższym okresie korzystania z API potrafi zmniejszać ogólne koszty nawet kilkukrotnie.
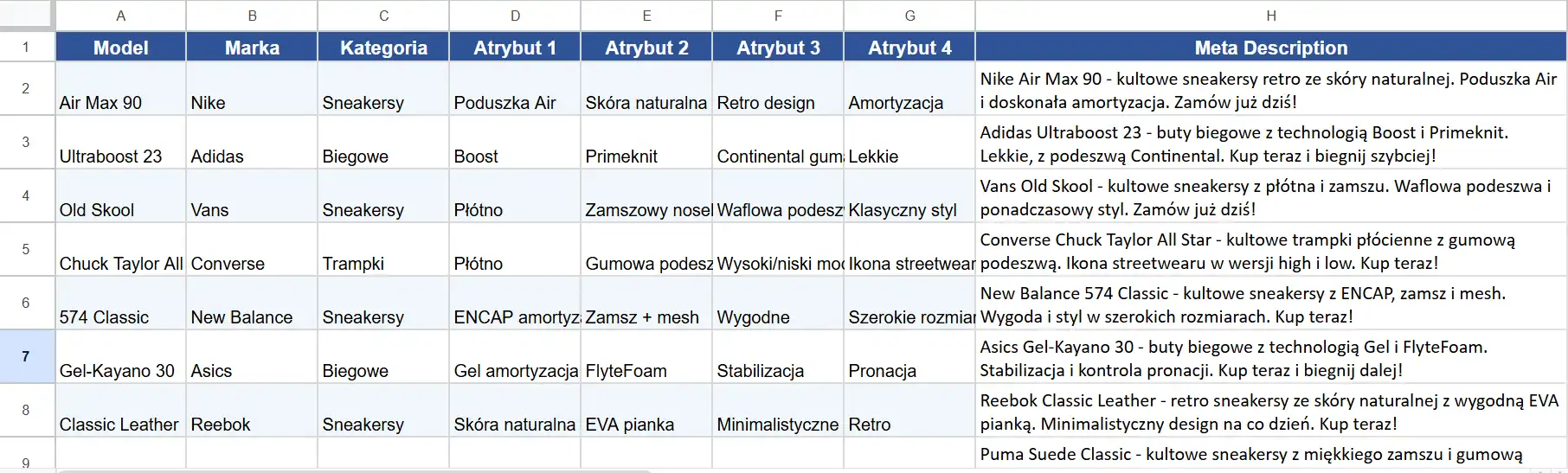
Krok 2: Wysyłamy 100 zapytań do API Claude z pliku Excel
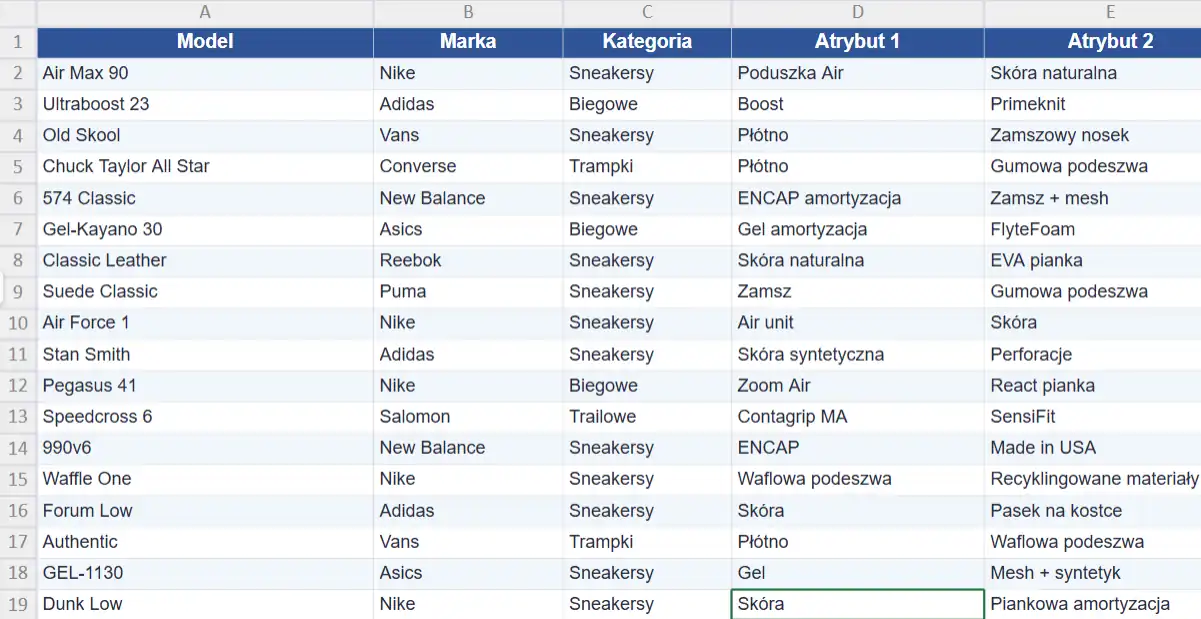
Z API modeli LLM nie korzysta się po to, żeby zadawać im pojedyncze pytania. Typowym zastosowaniem API Claude w SEO jest masowe generowanie treści. W kroku drugim naszym przykładem będzie lista produktów z pliku .xlsx, która posłuży do wygenerowania meta descriptions.
O ile sam mechanizm zapytania do API się w tym przypadku nie zmienia, musimy dostosować mechanizm jego wysyłania i zapisywania w ramach skryptu:
- w celu przetwarzania danych z arkusza kalkulacyjnego dodajemy bibliotekę
pandas, a w odczytywaniu i zapisywaniu plików pomoże zaimportowanieos, - w celu policzenia tokenów dla całości skrypt będzie zapisywał je w tablicy do przechowywania wyników wraz z każdą odpowiedzią API, a pod koniec sumował i drukował
- do generowania treści tego typu warto korzystać już z modelu Sonnet, a nie Haiku,
- prompt tworzył będzie się na podstawie zmiennych ustalonych na bazie treści ze wskazanych kolumn z pliku .xlsx
- aby poprawić jakość generowanych opisów, warto byłoby ustawić w system_message przykłady dobrych opisów i ewentualne wykluczenia dla kiepsko brzmiących sformułowań, nadużywanych w tego typu treściach przez LLM-y, na przykład w CTA.
Prosta propozycja do wypróbowania znajduje się w tej części skryptu, a przykładową bazę do pobrania wrzuciłem tutaj. Na tym jednak nie koniec naszych działań z API Claude.
Krok 3: Wczytujemy dane z Google Sheets i przetwarzamy w API Claude
O ile z przetwarzania plików Excel w Pythonie korzystam dość często do zadań typowo analitycznych, tak w przypadku generowania treści, wyciągania z nich określonych informacji czy tagowania znacznie wygodniej wczytuje się informacje z Google Sheets albo bazy danych (u mnie to self-hosted NocoDB, gdzie trzymam linki do badań, na podstawie których tworzy się krótki opis przygotowany przez AI, wysyłany potem przez REST API do repozytorium badań i statystyk na blogu).
W tym przypadku skrypt Python musimy poszerzyć po prostu o połączenie z Google Sheets:
- importujemy
gspreadorazCredentialszgoogle.oauth2.service_account, - podajemy dane uwierzytelniające połączenie z naszym kontem Google (ustawianie i pobieranie ich opisałem we wpisie na temat API z Google Cloud),
- tworzymy arkusz Google Sheets (musi być natywny, nie może to być importowany plik .xlsx), pamiętając o udostępnieniu go z opcją edycji,
- wskazujemy ID arkusza (znajduje się w adresie URL pomiędzy /d/ a /edit,
- wskazujemy, do jakiej kolumny powinna dostać się wygenerowana treść.
Jako że połączenie z API Google Sheets bywa zaskakująco kapryśne, przy większej ilości treści do wygenerowania polecam jednak łączenie się z sensowną bazą danych (NocoDB, Baserow lub Airtable), a w przypadku pozostania przy Sheetsach zamontowanie w skrypcie dużej liczby zabezpieczeń: pobieranie, przetwarzanie i dodawanie w batchach, sleep pomiędzy zapytaniami, mechanizm retry, szczegółowe debugowanie i czego tam jeszcze nie zaproponuje AI przy vibe code’owaniu.
Ciekawe funkcje API Claude AI
API Claude AI to oczywiście nie tylko wysyłanie promptów i odbieranie wygenerowanego tekstu. Powiedziałbym, że dopiero tutaj zaczyna się zabawa. Na co warto zwrócić uwagę?
Narzędzia (Tools)
Tool use (znany również jako function calling) to mechanizm, który pozwala modelowi wywoływać zdefiniowane narzędzia. W praktyce definiuje się zestaw dostępnych funkcji (np. „pobierz dane z API” czy „zapisz do bazy”), model decyduje, kiedy ich użyć, i zwraca odpowiedni request zamiast tekstu. Kod wykonuje funkcję i odsyła wynik do modelu, który na jego podstawie kontynuuje odpowiedź.
Ze względu na mnogość dostępnych opcji, w tym użytkowanie serwerów MCP, warto zapoznać się z rozdziałem dokumentacji poświęconym narzędziom. Zawiera on sporo przykładów użycia wywoływania funkcji w najróżniejszych sekwencjach i jeśli projekt wymaga nieco bardziej skomplikowanych operacji przy użyciu LLM-ów, będzie to złote źródło inspiracji. Trzeba tylko mocno uważać na overengeneering, żeby nie wbić się w rabbit hole wymuszania skomplikowanych sekwencji, w których wystarczyłaby podstawowa wiedza modelu, zamiast tokenożernego wywoływania wyszukiwania, fetchowania czy czego tam sobie nie wymyślimy.
Vision, czyli analiza obrazów i PDF-ów
Claude API przyjmuje nie tylko tekst, ale również obrazy i pliki PDF. Możesz więc wysłać do API zrzut ekranu, infografikę czy skan dokumentu i poprosić model o analizę, transkrypcję lub wyciągnięcie danych. Dane binarne wysyła się zakodowane w formacie base64, co Python SDK obsługuje w przystępny sposób.
Multimodalność otwiera ciekawe możliwości, gdy chce się wykorzystać informacje niedostępne w standardowych źródłach wiedzy. Information gain nie jest nowym konceptem w SEO, ale wykorzystanie API Claude do faktycznego uzyskania insightów ze źródeł zazwyczaj pomijanych w standardowych treściach internetowych ma szansę przenieść research na wyższy poziom.
Extended i Adaptive Thinking, czyli rozszerzone myślenie
Nowsze modele Claude oferują tryb extended thinking, w którym model „myśli” dłużej przed udzieleniem odpowiedzi. Proces myślenia jest widoczny w odpowiedzi (w osobnym bloku) i pozwala na głębszą analizę złożonych problemów. To przydatne przy zadaniach wymagających wieloetapowego rozumowania. Nie miałem jeszcze sposobności wykorzystania tego w zapytaniach do Claude API, ale przy vibe code’owaniu z Claude Code strasznie dużo dowiaduję się podczas spoglądania na bieżąco w przemyślenia modelu.
Anthropic poleca jednak używać trybu adaptive thinking, w którym to sam model definiuje zakres rozkminy potrzebny mu do wykonania powierzonego zadania. Ma być to docelowy sposób współpracy z Opus 4.6 i brzmi całkiem sensownie, ale nie miałem jeszcze do czynienia z tą opcją w praktyce.
Jak pisać odpowiednie prompty pod Claude API?
Pójdę zupełnie na przekór wszelkim zaklinaczom LLM-ów i powiem zupełnie szczerze: powtarzanie zasad pisania promptów uważam w 2026 roku za lekką obrazę inteligencji, podobnie jak wmawianie ludziom, że powinni klepać prompty od zera i jest to jakaś wybitnie skomplikowana umiejętność wymagająca kursów i certyfikacji.
Jeżeli chcesz uzyskać dobry prompt do API Claude, korzystasz z generatora promptów bezpośrednio w konsoli lub zwyczajnie prosisz dowolny LLM o skonstruowanie takiego, podając w sumie trzy rzeczy:
- Przykład pożądanego outputu (jeśli nie masz, to krótki opis, LLM coś sklei).
- Format odpowiedzi (HTML, markdown, JSON).
- Określenie roli i tonu (też bez przesady z uszczegółowianiem).
I dopiero na tym etapie zaczyna się cała zabawa. Sztuką nie jest bowiem stworzenie promptu, ale optymalizacja całego procesu. Dotyczy to zarówno jakości outputu (ocena „na oko” jest wbrew pozorom totalnie sensowna, ale prowadzić może do prób zbyt sztywnego kontrolowania outputu poprzez prompt, co paradoksalnie prowadzi do coraz gorszych wyników, więc prędzej czy później trzeba poznać metody ewaluacji mechanicznej), jak i kosztów (mechanizmy związane z asynchronicznym batch processing wyceniane są przez Anthropic dwa razy taniej niż standardowe przetwarzanie). To jednak materiał na nieco inną historię…
Te artykuły powinny Cię zainteresować
O autorze
Nazywam się Michał Małysa i od wielu lat zajmuję się zawodowo SEO oraz analizą treści, a od 2023 roku w zakres moich obowiązków i zainteresowań dość naturalnie weszło AI. Na stronie MałySEO porządkuję wiedzę o pozycjonowaniu stron internetowych, AI Search oraz działaniu LLM-ów. Prowadzę również MałySEO Newsletter, do którego subskrypcji serdecznie Cię zachęcam na podstronie najlepszego w Polsce newslettera SEO.
Jako że przygotowanie materiałów do MałySEO Newslettera oraz na bloga zajmuje nieco czasu, może zaświtać Ci w głowie dość miły z mojej perspektywy pomysł drobnego rewanżu. Jeżeli uznasz, że lektura tego wpisu była dla Ciebie czymś więcej, niż tylko szybkim odklepaniem randomowej internetowej treści, możesz postawić mi kawkę na buycoffee.to. Z góry dziękuję!

Jeżeli z jakiegoś powodu potrzebujesz się ze mną skontaktować, wyślij mail na adres kontakt[at]michalmalysa.pl