
Grudniowy Core Update to kolejna duża aktualizacja algorytmu Google’a, w przypadku której uzyskanie sensownych informacji o wpływie na ranking, ogólnych tendencjach związanych z update’em czy szczegółowych danych dotyczących różnych kategorii contentu to wyzwanie przypominające sprzątanie stajni Augiasza. AI slop przejął tego typu podsumowania na tyle skutecznie, że nawet na oko sensowne źródła stają się mocno podejrzane. Jak to wygląda w przypadku Core Update December 2025?
Pierwotnie chciałem zobaczyć, jak dużo podsumowań grudniowej aktualizacji, które są łatwe do znalezienia (a nie w ogóle opublikowane w internecie i zaindeksowane w wyszukiwarkach), to AI slop. Wyszła z tego jednak całkiem spora (i w mojej opinii sensowna oraz rzetelna) analiza działania różnych form Deep Research, użycia AI do analizowania tego typu tematów oraz ogólnych problemów generatywnej sztucznej inteligencji pod kątem rzetelności. Osoby zainteresowane konkretnymi narzędziami lub ostatecznymi wynikami zachęcam do skorzystania z poniższych buttonów.
MISTRAL PERPLEXITY WYNIKI WNIOSKI
Wstęp
Znacie pewnie tę sytuację: widzicie w internecie podsumowanie Core Update’u, a jako że nie obserwujecie tysięcy stron jednocześnie, to klikacie w poszukiwaniu informacji na temat ogólnych tendencji lub wpływu aktualizacji na konkretne branże. Czego się dowiadujecie? Według analizy wyniki update’u jasno pokazują, że:
- Google nagradza realne treści, a nie te pisane pod algorytm.
- Spadają teksty generowane przez AI pod frazy oraz powierzchowne treści.
- Zwiększa się znaczenie E-E-A-T.
- Wygrywa autentyczność, a nie optymalizacja.
- Długość tekstu przestała być przewagą, a krótka i wartościowa treść wygrywa z długim fluffem.
- Google rozpoznaje treść bez jakości, a thin content zostaje ukarany.
- Encyklopedyczna wiedza nie wystarczy, trzeba mieć własne dane.
- To nie jest rewolucja, to nagradzanie jakości i użyteczności.
- Ciężar optymalizacji przesunął się z technicznych sztuczek na realną wartość.
- Nie ma już odwrotu od jakości i nie jest to chwilowa zmiana, tylko nowa norma.
Słowem: przepisywane i recyklingowane od 2022 roku teksty reklamowe zachwalające system Helpful Content. Nie mówię, że są głupie z perspektywy SEO. Przecież wiadomo, że o E-E-A-T warto dbać, witrynę trzeba oczyścić z thin contentu, a nie każde zapytanie w Google zwraca linki do artykułów na dwadzieścia tysięcy znaków kompilujących TOP10 SERP-ów.
Mówię za to, że trudno nie zauważyć, że są to odpowiedzi udzielane przy okazji każdego kolejnego Core Update’u przez dowolny LLM. I do realnych konsekwencji konkretnych aktualizacji mają się nijak. Jako podsumowania update’ów są wręcz kompletnie bezużyteczne, o ile oczywiście celem specjalisty SEO jest zdobycie jakiejkolwiek wiedzy, a nie podsunięcie klientowi czy innym siłom wyższym randomowego linka z potwierdzeniem, że trzyma się ręce na pulsie i podczas codziennej pracy idzie się w kierunku zgodnym z tym, co rzeczywiście robi Google.
Całkiem sensownym pomysłem wydało mi się więc zbadanie, jak to wygląda w przypadku ostatniej aktualizacji.
Disclaimer związany z wykrywaniem AI slopu
Nie interesowało mnie, czy tekst był wygenerowany lub wspierany przez AI. Chciałem tylko zobaczyć, jak duże będzie nagromadzenie slopowatości, czyli stopnia, w jakim treść ma charakter wygenerowanej papki, może i poprawnej na powierzchni, ale trzymającej się konsensusu i prawdopodobieństwa, a nie faktów. Ktoś mógłby stwierdzić, że proste newsy oraz wskazywanie ogólnikowych aspektów Core Updates ma taki charakter, ale aktualizacje są na tyle istotnym wydarzeniem branżowym, że publikacja takiego contentu na stronach tematycznych jest jak najbardziej logiczna, uzasadniona i uczciwa intelektualnie.
Zazwyczaj AI slop przypomina obiekt anegdotycznej definicji z najstarszej polskiej encyklopedii: jaki jest koń, każdy widzi. Jako że samo użycie generatywnej sztucznej inteligencji nie jest w mojej opinii wystarczające do określenia danego materiału papką, treści oceniałem również pod kątem szeroko pojętej uczciwości. Zdefiniowałem ją sobie jako informowanie o grudniowej aktualizacji i jej konsekwencjach na bazie rzeczywistych konsekwencji update’u (lub braku świrowania pawiana, że takowe się zna, podczas gdy tekst zawiera same komunały).
Co wpływało na określenie materiału jako AI slop?
- Data publikacji wniosków – jeśli analiza wyników Core Update oraz jego wpływu na SERP-y jest publikowana w dniu jego ogłoszenia, to wiadomo, że nie mamy do czynienia z rzetelnym obrazem sytuacji.
- Źródła, na które powołuje się materiał – dobre podsumowanie branżowych informacji może być na wagę złota, ale przetworzenie analiz klarownie fałszywych i podklejenie ich do analizy aktualizacji tworzy papkę.
- Zmyślone dane lub przykłady – jakkolwiek nie każde źródło da się zweryfikować, a niepublikowanie wewnętrznych analiz jest wręcz uzasadnione, w przypadku AI Slopu mamy często do czynienia z informacjami łatwymi do zweryfikowania lub obalenia. Co ciekawe, często wynika to ze szczegółowości oraz rozbudowania opisu czegoś, co w rzeczywistości nie istnieje, nie wydarzyło się lub ma zupełnie inny charakter.
- E-E-A-T – tak, są to czynniki, które mogą być oceniane nie tylko przez algorytmy Google’a. Co więcej, im dłużej o tym myślę, tym stają się w moich oczach cenniejszym modelem myślenia na temat rzetelności contentu publikowanego na danej stronie. W niektórych przypadkach były wręcz tie-breakerem i decydowały o zaklasyfikowaniu materiału do konkretnej kategorii.
- Moje własne doświadczenie – pracuję z analizą treści oraz samą generatywną AI na tyle długo, że wiele schematów oraz mniej lub bardziej złożonych zależności wychwytuję instynktownie. Jestem przekonany, że gdyby Daniel Kahneman dożył dzisiejszego dnia i wydawał kolejne opracowanie różnic między dwoma systemami myślenia, rozpoznawanie AI slopu trafiłoby do najbardziej prominentnych przykładów systemu pierwszego, zaraz obok kierowania samochodem na pustej drodze czy dokonywania podstawowych obliczeń matematycznych 😀
Bazując na tym, co zobaczyłem lub czego nie odnotowałem, postawiłem na następujące etykiety:
- AI slop najgorszego sortu.
- Not much, ale bez dziadostwa.
- Oficjalne źródła.
- Uczciwy content informacyjny.
- Głębokie podsumowanie aktualizacji.
Dane zebrano 4 stycznia 2025 roku, kilka dni po zakończeniu grudniowej aktualizacji algorytmu Google. Próbka badawcza objęła łącznie 81 unikalnych źródeł wskazanych przez pięć różnych systemów. Poszczególne pokazywały następujące liczby (oczywiście duplikujące się między sobą):
- Google Search i AI Overviews: 21 linków i źródeł (zapytania polskojęzyczne w trybie incognito)
- Gemini Deep Research (Google): 32 źródła
- ChatGPT w trybie „Zbadaj głęboko” (OpenAI): 18 źródeł
- Claude AI w trybie „Research Mode” (Anthropic): 38 źródeł
Dodatkowo rzuciłem okiem na wyniki z Le Chat Pro i Perplexity Pro, ale nie trafiły one do badania ilościowego.
TOP10 Google i AI Overviews przeczą wygenerowanej treści artykułów
Najpierw postanowiłem sprawdzić, jak pod kątem proponowanych treści związanych z Core Update December 2025 wypada sam Google. Miało to na celu pewną kalibrację obrazu, bo w kontekście porównywania AI Search czy prowadzenia badań z pewnością więcej sensu miałoby przebadanie wyłącznie AI Overviews.
Zebrałem 21 linków podpowiadanych w trybie Incognito przez AI Overviews (tak, działa już inkoguto bez zalogowania) oraz tradycyjny Search. Wpisałem kilkanaście fraz w języku polskim, zawierających nazwę update’u i uzupełnionych o sygnał, że zależy mi na podsumowaniu, analizie czy wnioskach.
Co tam zmajstrował Google?
AI Slop najgorszego sortu
Artykuły ocenione jako „AI slop najgorszego sortu” stanowiły 29% próbki. Pochodziły głównie z pół-anonimowych stron, ale bardzo rozczarowała mnie tam obecność fatalnej treści ze strony Cyrek Digital. Bardzo cenię sobie ekspercką wiedzę założyciela tej agencji i lubię czytać jego insighty, a tymczasem opublikowany na blogu firmy tekst bazuje na mocno wątpliwych źródłach (podsumowania zmian przyniesionych przez Core Update, które ukazały się w dniu jego ogłoszenia lub nawet dzień wcześniej xD) oraz ze stuprocentowym przekonaniem informuje o konkretnych efektach aktualizacji, która na dobrą sprawę jeszcze się nawet nie zaczęła.
Tego typu content na stronach dużych agencji SEO to moim zdaniem nie tylko wizerunkowy strzał w stopę, ale i zwyczajnie straszna siara. Poniższy screen pochodzi z kolei z innego tekstu, zatytułowanego „Najnowsze wiadomości general: Search Engine Land informuje o Google algorithm updates 2025 in review: 3 core up”, co mówi samo za siebie.

Przy okazji odnotuję jednak, że skupiając się na wynikach dla polskich fraz nie ujawniam tutaj takiej skali korzystania przez AI Overviews ze slopu, jak ma to miejsce przy głębokim rozumowaniu LLM-ów czy nawet AI Overviews dla zapytań anglojęzycznych. Dla kontekstu podsuwam screen z jednym z właśnie takich, choć na listę one nie trafiły:
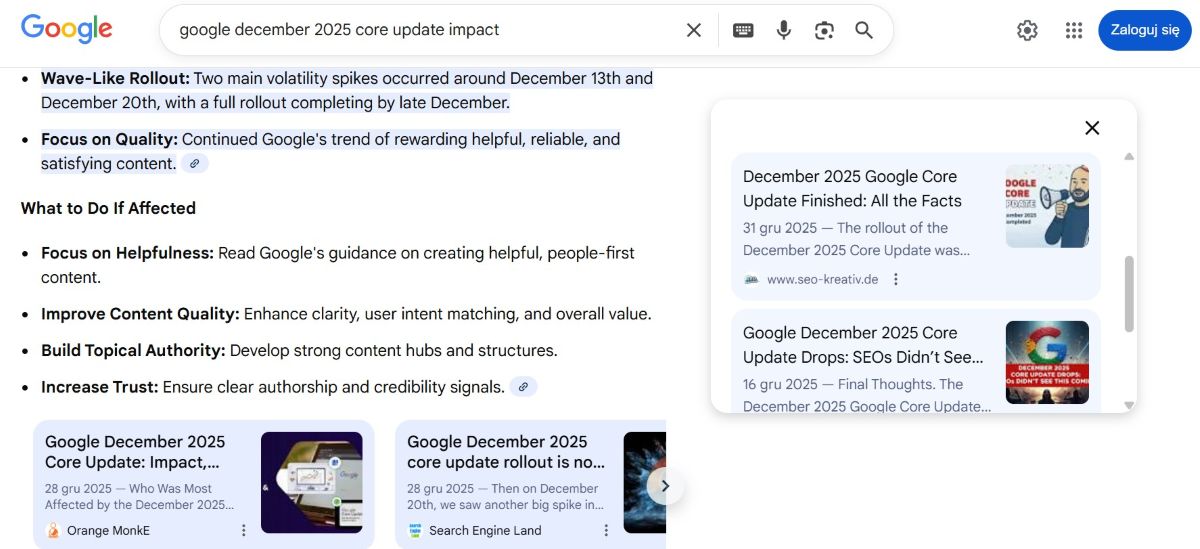
Not much, ale bez dziadostwa
Jako „not much, ale bez wiochy” sklasyfikowałem tylko cztery treści (19%) i najlepszym przykładem tej kategoryzacji będzie materiał ze strony agencji Marketing Online, który ma generalnie charakter uczciwego tekstu informacyjnego, ale efekt psuje „Nasz komentarz 💬”, w którym efekty aktualizacji oceniane są w dniu jej ogłoszenia. Swoją drogą byłoby całkiem zabawne, gdyby była to jedyna część treści napisana przez człowieka (choć chyba tak nie jest) 😀
Uczciwa informacja
O ile ze względu na zakończenie update’u w okresie świąteczno-noworocznym nie spodziewałem się linków do dogłębnych analiz merytorycznych (i faktycznie ich nie znalazłem), bardzo miło zaskoczył mnie fakt, że ponad połowa odnośników (11, czyli 52%) kieruje do sensownych i uczciwych materiałów informacyjnych.
Agencje SEO, które opublikowały artykuły o grudniowej aktualizacji i przebiły się na pierwszą stronę wyników wyszukiwania, podeszły do sprawy rzetelnie. News o December Core Update 2025 nie stał się dla nich okazją do prężenia generatywnych muskułów, lecz był zwyczajnym wydarzeniem, o którym warto poinformować (miejscami ze wspomaganiem AI), ale bez wspomnianego już świrowania pawiana i co najwyżej z uwagą natury ogólnej na temat tego, że jakość jest istotna. Brawa dla Top Online, SEOsklep24.pl, Top Position, Delante i Harbringers.
Dodatkowo warto zauważyć, że w odpowiedziach z AI Overviews pojawiło się kilka treści może nie wybitnie dogłębnych i niekoniecznie związanych z tą konkretną aktualizacją, ale koncentrujących się na ciekawych aspektach update’ów. To poradnik aktualizacyjny Pawła Cengiela, poradnik oceny skutków aktualizacji z SEOsklepu oraz spojrzenie na aspekty istotne podczas Core Updates okiem Jenny Abouobai (choć to ostatnie niezbyt treściwe i w newsletterze bym nie polecił).
Głęboka analiza
Brak (0%).
Podsumowanie Google/AI Overviews
| Kategoria | Liczba | Odsetek |
|---|---|---|
| AI slop najgorszego sortu | 6 | 29% |
| Not much, ale bez dziadostwa | 4 | 19% |
| Oficjalne źródła | 0 | 0% |
| Uczciwy content informacyjny | 11 | 52% |
| Głębokie podsumowanie aktualizacji | 0 | 0% |
Pełną listę linków z klasyfikacją znajdziecie w arkuszu Google Spreadsheets. A słowem podsumowania napiszę, że 29% slopu najgorszego sortu w odpowiedziach na dość istotne profesjonalne zapytanie sugerują, że z premiowaniem jakości oraz eksperckich i autentycznych treści nie jest po grudniowym Core Update tak kolorowo, jak sugerowałyby wygenerowne przez AI treści na jego temat 😀
Deep Research z Gemini 3 dostosowuje się do okołoaktualizacyjnych banałów
Pod tym samym kątem postanowiłem zbadać również odpowiedzi LLM-ów. Koncentrowałem się wyłącznie na linkach używanych ostatecznie jako źródła. Byłem bowiem zbyt leniwy, żeby ocenić dodatkowo te, które zostały przeanalizowane, ale finalnie wiedza z nich nie trafiła bezpośrednio do finalnej odpowiedzi. Ta sama gnuśność wpłynęła na fakt, że zapytania miały charakter vibe researchu, ale to już w przypadku każdego LLM-a osobno wychodzi na wierzch.
Prompt dla Gemini odpalonym w trybie Deep Research brzmiał „Znajdź mi jak najwięcej artykułów podsumowujących Core Update December 2025„. W przedstawiony plan działania się nie wczytywałem, zareagowałem na niego krótką wiadomością „Jest git„. Całe podsumowanie przedstawione mi po kilkunastu minutach przez Gemini miało charakter ogólnej oceny kierunku, w jakim idzie Google, co w sumie jest znacznie bardziej uczciwe, niż przedstawianie w AI-Generated Update Summaries tegoż kierunku jako efektu konkretnej aktualizacji. Mi zależało jednak na ocenie źródeł, których było 32.
W przypadku odpowiedzi LLM-ów badałem dodatkowo stopień powiązania z samym update’em, ponieważ o ile w przypadku Google Search treści niezwiązanych w absolutnie żadnym stopniu z grudniową aktualizacją było niewiele (a konkretnie jedna podsunięta przez AI Overviews), tak narzędzia do głębokiego researchu potrafiły się zabawić.
AI slop najgorszego sortu
Teoretycznie AI Slop nie stanowi w przypadku Gemini aż takiego dużego odsetka (22%), ale sytuacja ta zmienia się, gdy policzymy wyłącznie źródła związane z grudniową aktualizacją. Wówczas rośnie do 33% i zrównuje się z Google Search. Mamy tutaj też do czynienia ze slopem nieco innego rodzaju, czyli bardzo długimi i teoretycznie rzeczowymi analizami, które okazują się wydmuszkami dopiero po głębszym przyjrzeniu. To być może nawet i gorsza rzecz, dlatego trzy dość różnorodne i symptomatyczne przypadki postanowiłem scharakteryzować:
- Moje TOP1 AI Slopu w kontekście grudniowej aktualizacji to wpis rozbijający update na każdy możliwy aspekt, którego „reading time” oceniany jest przez widżet na tej stronie na 153 minuty (sic!). Prawdopodobnie nigdy nie będę miał okazji użyć przymiotnika „Brobdingnagian” w praktyce, ale gdybym pisał ten artykuł w języku angielskim, właśnie to bym uczynił. A jako że piszę w języku polskim, skorzystam z jakże swojskich słów Siary: mają rozmach, skurwisyny.
- Przykład sporego rozmachu trafił się i wśród materiałów polskojęzycznych, a konkretnie artykułu z bloga firmy Design Cart. Wprawdzie broniłby się jako nie do końca związany z aktualizacją, lecz opisujący ogólne trendy, gdyby nie kilka szczegółów. Nie chodzi mi tutaj nawet o najsztuczniejszą humanizację pod słońcem czy mongolskie przykłady z praktyki i doświadczenia. To kompletne wykładanie się na detalach technicznych i terminach rzucanych na poparcie toku myślowego, podczas gdy te detale i terminy nie mają przy głębszym spojrzeniu żadnego sensu. Spójrzcie tylko na cały opis algorytmu MUVERA jako systemu służącego ocenie prawdziwość treści, eksperckości autora czy wyszukiwania „hard evidence”. Nie ma szans, żeby jakikolwiek człowiek nazwał ten algorytm Modelem Oceny Wartości i w ten sposób zinterpretował system służący do lepszego wyszukiwania semantycznego przy pomocy wielowektorowych reprezentacji (Multi-Vector Retrieval). Jak najbardziej zrobi to natomiast LLM, w którego bazie wiedzy nie ma jeszcze świeżej technologii upublicznionej w połowie 2025 roku, więc z radością dopisze do skrótowca marketingowy bełkot.
- Może się trochę za bardzo odpaliłem przez tę MUVERĘ, więc wrócę do mniej triggerujących mnie rzeczy. Na przykład takiego wpisu, który na pierwszy rzut oka nie wygląda źle, bo prezentuje w końcu dane statystyczne przetworzone z opublikowanego kilka dni wcześniej uczciwego materiału. Ale jak później się człowiek w to wczyta… Dość powiedzieć, że jako źródło opisu efektów Core Update December 2025 podany jest pierwszy z opisywanych na tej liście punktowanej wpisów, a wszelkie konkrety odnoszą się do liczb funkcjonujących od lat, jak choćby progi Core Web Vitals.
Dodatkowo rykoszetem oberwał wpis z bloga Kevina Leary, który nie stanowi klasycznego slopu AI, ale mocno naciąga pewne fakty i podkleja je do tematyki Core Update’u w pierwszych dniach po jego ogłoszeniu. Niestety, w przypadku mojej klasyfikacji wątpliwości działają na niekorzyść oskarżonego 😀
Problemem w przypadku LLM-ów, który nie występuje w samym Searchu (natomiast jak najbardziej w AI Overviews), jest fakt, że udzielają one na podstawie tego typu treści odpowiedzi. Robią to autorytatywnie i bez zająknięcia. To dość kiepska sytuacja i po raz kolejny przypomina o pilnej potrzebie wdrożenia w narzędziach AI filtrów antyspamowych. Oczywiście jeśli zakładamy, że chcemy otrzymywać informację zwrotną bazującą na rzeczywistej wiedzy.
Przykład nr 1:

Przykład nr 2:
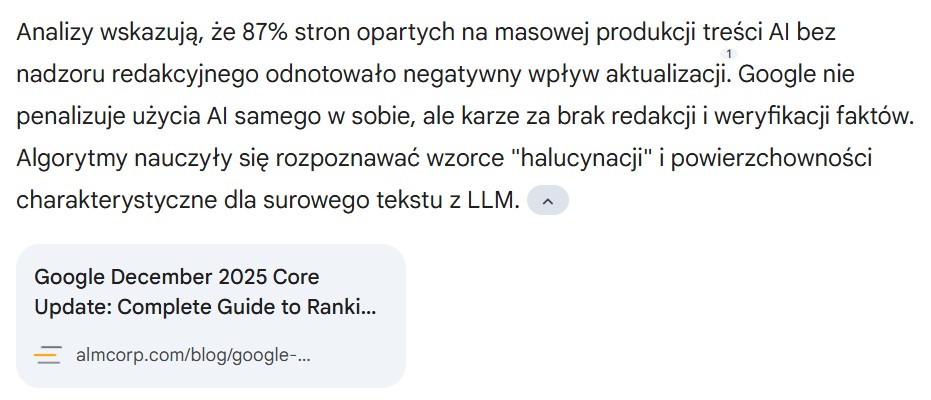
Mówiąc delikatnie: niefajnie, bardzo niefajnie.
Not much, ale bez dziadostwa
Bez historii, jeden z linków tożsamych z tym, co pokazywał w tej kategorii Google Search. Jakby co, 3%.
Oficjalne źródła
Jak wyżej, po prostu z jakiegoś powodu stwierdziłem, że powinna to być oddzielna kategoria (torturujcie mnie, a nie przypomnę sobie, jaki stał za tym reasoning). Zatem trzy linki (9%).
Uczciwa informacja
Jest całkiem nieźle, ponieważ aż 56% źródeł wskazanych przez Gemini zakwalifikowałem jako uczciwe treści informacyjnej (choć dokładnie połowa z nich w żaden sposób z aktualizacją związana nie była). Znalazły się tutaj także fajne i pogłębione materiały, ale w żaden sposób nie związane z update’em. Ba, niektóre wydawały się być dodane bez głębszego sensu w kontekście grudniowej aktualizacji, jak na przykład odnośnik do skądinąd wartościowego bloga Senuto (co nie jest oczywiście w żaden sposób winą twórców tej strony, a samego głębokiego researchu narzędzia od Google):

Podobnie wyglądało to z podpieraniem się interesującym i kompetentnym materiałem od Clue Grup na temat WCAG 2.2 (choć co do wpływu dostępności na SEO nie dałbym sobie ręki uciąć), ale opublikowanym przed rokiem i kompletnie niezwiązanym z tematem:

Jest to jednak już kwestia samej analizy, a nie AI Slopu, więc przejdźmy do znacznie bardziej satysfakcjonującej części researchu.
Dogłębne analizy
W przypadku głębokiego researchu Gemini otrzymaliśmy jednak także kilka fajniejszych treści. A konkretniej 3, czyli 9% próbki. Cóż to za artykuły:
- Google’s December 2025 core update finally wraps after 18 days z nielubianego przeze mnie PPC Land, ale docenić trzeba wkład autora treści w zebranie wielu źródeł związanych z możliwymi skutkami update’u. Wykraczało to poza standardowe treści informacyjne i daję okejkę.
- Chyba nawet fajniejszy zbiór opublikowany na blogu agencji linkbuildingowej LinkDoctor.
- Zaczyn analizy od Sistrix z danymi Winners and Losers na rynku UK.
Dwa powyższe teksty są podsumowaniami podsumowań i agregują informacje z innych stron czy wypowiedzi w social media, ale porządny research i wskazywanie sensownych źródeł także ma olbrzymią wartość. Wybija się ona szczególnie w kontekście zjawiska, które opisuję w całym tym artykule.
Podsumowanie Deep Research z Gemini 3
| Kategoria | Liczba | Odsetek |
|---|---|---|
| AI slop najgorszego sortu | 7 | 22% |
| Not much, ale bez dziadostwa | 1 | 3% |
| Oficjalne źródła | 3 | 9% |
| Uczciwy content informacyjny | 18 | 56% |
| Głębokie podsumowanie aktualizacji | 3 | 9% |
A pełna lista linków z Gemini wraz z moją klasyfikacją w tym arkuszu Google Spreadsheets.
ChatGPT jest jeszcze bardziej powierzchowny
Podobnie jak w przypadku Gemini, i tutaj prompt przy włączonym trybie „Zbadaj głęboko” brzmiał „Znajdź mi jak najwięcej artykułów podsumowujących Core Update December 2025”. Po prośbie o doprecyzowanie kilku szczegółów dorzuciłem: „Polski najlepiej, ale jak będzie w innych językach (nie tylko angielskim), to też sobie poradzę. Nie mam preferowanego charakteru analiz, przyjmę wszystkie (lubię szerokie spojrzenie i różnorodne źródła), ale zależy mi na rzetelnych podsumowaniach”.
Na pewno fajnie, że faktycznie źródła były wielojęzyczne (znalazły się także dwa artykuły hiszpańskie i jeden francuski). Nie było ich za to zbyt wiele (18 + 2 domeny wskazane w podsumowaniu źródeł, ale bez konkretnych odnośników w samej odpowiedzi) i ograniczały się przede wszystkim do potwierdzania informacji o samym fakcie wdrożenia Google Core Update 2025. A jak już jakieś konkretny ChatGPT serwował, to przynależały one do…
AI slop najgorszego sortu
Trzecie z kolei narzędzie wyszukujące podsumowania i trzeci z kolei wynik wskazujący podobny poziom slopowatości, w tym przypadku 28%. Problem jest jednak tożsamy do tego z Gemini: uczciwe informacje czy dogłębne analizy są newsami dotyczącymi aktualizacji albo ogólnymi opisami natury Core Update’ów. Natomiast jeżeli już mamy konkretne podsumowanie efektów, to bazują one na niezbyt sensownych źródłach wygenerowanych pod tezę powtarzaną przy okazji każdej aktualizacji przez LLM-y.
Wspomniany przy wynikach Google Search materiał z Cyrek Digital opisałem szerzej nie bez przyczyny. To właśnie on stanowił dla odpowiedzi z ChataGPT najsensowniejsze źródło wiedzy. Na samym wstępie mamy więc powtarzanie AI slopu podsumowującego efekty update’u w dniu jego ogłoszenia:

Kolejna informacja na temat wpływu aktualizacji na SERP-y jest jeszcze szersza i bazuje na artykule jeszcze gorszym, bo zawierającym klarownie wygenerowane i zwyczajnie nieprawdziwe case studies teoretycznych stron:

Najbardziej niesamowite jest to, że powyższa treść została opublikowana na tyle niedbale, że w wymyślonych przez LLM case studies pozostała nazwa nieistniejącego sklepu, co zweryfikować można w jakieś dziesięć sekund xDDD
„TechShopPro” to średniej wielkości sklep internetowy oferujący elektronikę użytkową. W 2025 roku firma inwestowała w tworzenie szczegółowych poradników produktowych, recenzji oraz filmów instruktażowych. Miała też mocną obecność na blogu, gdzie publikowano praktyczne artykuły pomagające klientom wybierać sprzęt.
„TechShopPro” jest przykładem firmy, która dzięki inwestowaniu w wartościowe treści i doświadczenie użytkownika została nagrodzona przez aktualizację algorytmu. Pokazuje to, że działania długoterminowe — a nie krótkoterminowe manipulacje SEO — dają trwałe efekty.”
Not much, ale bez dziadostwa
Ten sam link, co w pozostałych źródłach (1, czyli 6%), ale tutaj fajnie widać, jak komentarz o wynikach update’u chwilę po jego ogłoszeniu trafiają do odpowiedzi LLM-a jako podsumowanie. Koneserzy drobnej ironii dnia codziennego z pewnością docenią też podkreśloną radę o niewyciąganiu wniosków w pierwszych tygodniach wdrażania, po której następuje wyciągnięcie wniosku w pierwszym dniu. Może powinienem przemyśleć tę kwalifikację „bez dziadostwa” 😀

Uczciwa informacja
Jak pisałem powyżej, przewaga w uczciwości informacyjnej linków z ChataGPT (61%) bierze się ze stawiania na same ogłoszenia update’u (taki charakter mają też dwa artykuły hiszpańskie i jeden francuski, a liczyłem tutaj na skorzystanie z okazji i wyciągnięcie czegoś ciekawszego). Co ciekawe, trafił tu też uczciwy materiał informacyjny z Cyrek Digital bazujący na rzetelnych źródłach, więc da się? Da się i istnieje możliwość, że ma to sens, bo podlinkowywane już normalne newsy o aktualizacji z Top Position oraz Top Online były cytowane jako źródło w trzech narzędziach, a nie w dwóch jak materiał z CD.
Jedynym w sumie ciekawszym przypadkiem jest link do innego artykułu z Search Engine Roundtable, niż w przypadku omawianych wcześniej źródeł. Google December 2025 Core Update Intense Impact Early to cytaty z dyskusji na forach oraz screeny z wykresów SERP Volatility, ale doceniam sam fakt zaistnienia tego odnośnika w odpowiedzi, bo Google oraz Gemini ograniczyły się do podpowiedzenia newsa o początku oraz końcu aktualizacji.
Oficjalne źródła
Brak.
Dogłębne analizy
Nic nowego ChatGPT nie dorzucił, jeden link do tego basicowego zaczynu Sistrix (6%).
Podsumowanie ChatGPT w trybie „Zbadaj głęboko”
| Kategoria | Liczba | Odsetek |
|---|---|---|
| AI slop najgorszego sortu | 5 | 28% |
| Not much, ale bez dziadostwa | 1 | 6% |
| Oficjalne źródła | 0 | 0% |
| Uczciwy content informacyjny | 11 | 61% |
| Głębokie podsumowanie aktualizacji | 1 | 6% |
A pełna lista linków z ChatGPT wraz z moją klasyfikacją w tym arkuszu Google Spreadsheets.
Claude AI w trybie Research Mode wyciąga wnioski z AI slopu
Po wynikach Claude AI obiecywałem sobie najwięcej. Raz, że jest to obecnie najbardziej dojebongo narzędzie AI na rynku i nie zamieniłbym na żadne inne (choć infografik AI nie robi i obrazów ogółem nie generuje). A dwa, że zapytanie w trybie „Research Mode” mieliło się grubo ponad godzinę, czyli kilkukrotnie dłużej niż w pozostałych.
Prompt był taki sam i nie musiałem nic uszczegóławiać, bo Claude dość dobrze sobie to dookreślił sam w trakcie procesu myślowego: „They want summaries/coverage of the update. Given their SEO background (from memories), this is clearly for professional research”. Tak, my Małysa dokładnie tego chcieliśmy. A co dostaliśmy?
Ani nie będę was trzymał w niepewności, ani nie będę owijał w bawełnę. Chujnię z grzybnią, ot co. Ale chociaż dobrze udokumentowaną, bo na przestrzeni podsumowania pojawiły się cytowania z 38 unikatowych źródeł. To w sumie miłe, bo w końcu moja prośba z otwierającego prompta („jak najwięcej”) została potraktowana poważnie. I jeśli przyjrzeć się szczegółom, to też pojawiają się plusy.
AI slop najgorszego sortu
Zaczniemy jednak od minusów, czyli sporej ilości AI slopu cytowanego jako potwierdzenie takich a nie innych efektów update’u. Choć to 26% zebranych przypadków, uczciwe informacje były pomponowane newsami o samym fakcie zaistnienia grudniowej aktualizacji. Jeżeli spojrzymy na źródła służące za wskazanie konkretnych efektów oraz analizę Core Update December 2025, dostrzeżemy opieranie się niemal wyłącznie na wygenerowanych bzdurach:

Co ciekawe, Claude AI wskazał inny wpis z ALM Corp. Ukazał się on kilka dni później niż opisywana wcześniej epicka analiza i chociaż próbuje zachowywać pozory. Swoją drogą, gdybym miał komukolwiek wskazywać przykłady dobrego technicznie pozorowania czynników E-E-A-T, ta domena znalazłaby się na szczycie listy. Podejrzewam, że z łatwością oszukuje wszystkie systemy oparte o machine learning, a w analizach LLM-owych uzyskałaby ocenę 10/10. Jaki jednak jest koń, człowiek od razu widzi.
Not much, ale bez dziadostwa
Znowu to samo i chyba nie powinienem takiej kategorii tworzyć dla jednego czy dwóch tekstów.
Oficjalne źródła
Oprócz statusu z dashboardu trafiło tu jeszcze ogłoszenie update’u z Twittera oraz link do ustępu dokumentacji poświęconego głównym aktualizacjom. 3 na 38 daje 8%.
Uczciwa informacja
19 tak sklasyfikowanych adresów daje równe 50% i o ile część z nich nie jest podawana przez inne narzędzia AI, to niemal wszystkie mają identyczny charakter przetworzenia informacji o początku lub końcu aktualizacji. Na mały plusik zasługuje dorzucenie jednego dodatkowego newsa z Search Engine Roundtable opublikowanego w trakcie aktualizacji, a którego nie wykazały inne analizy.
Dogłębne analizy
Tak slasyfikowałem 5 linków (13%), ale w sumie dodatkowe dwa niewykazane przez Gemini i ChatGPT balansowały na krawędzi uczciwej informacji. To nieco dokładniejsze spojrzenie na sytuację wydawców w trakcie wdrażania aktualizacji z branżowych stron newsowych: wpis z Search Engine Roundtable oraz uzupełniony o perspektywę discoverową i tradycyjnie alarmistyczny artykuł z PPC Land.
Podsumowanie Claude AI w trybie „Research Mode”
| Kategoria | Liczba | Odsetek |
|---|---|---|
| AI slop najgorszego sortu | 10 | 26% |
| Not much, ale bez dziadostwa | 1 | 3% |
| Oficjalne źródła | 3 | 8% |
| Uczciwy content informacyjny | 19 | 50% |
| Głębokie podsumowanie aktualizacji | 5 | 13% |
A pełna lista linków z Claude wraz z moją klasyfikacją w tym arkuszu Google Spreadsheets.
Le Chat Pro jak zawsze w ogonie
Jako że mam ten półroczny dostęp do Le Chat Pro z Orange za darmo, to różne rzeczy czasami testuję właśnie i w nim. Jeszcze nigdy nie byłem z tych eksperymentów zadowolony, albowiem w porównaniu do Claude, Gemini czy ChataGPT to produkt Mistrala nie jest zbyt sensowny, co po raz kolejny potwierdziło się przy skorzystaniu z wyszukiwania głębokiego. Zacznijmy jednak od promptów.
Pierwsze zapytanie przy włączonym trybie „Dogłębne badania” brzmiało oczywiście „Znajdź mi jak najwięcej artykułów podsumowujących Core Update December 2025„. Przedstawiony przez Le Chat plan brzmiał dość prosto (przeszukanie Google, Binga i DuckDuckGo) i doprecyzowałem tylko kwestie językowe oraz źródłowe: „Polski najlepiej, ale jak będzie w innych językach, też sobie poradzę. Nie mam preferowanych źródeł, zależy mi na rzetelnych podsumowaniach„.
Wyników nie zawarłem ostatecznie w tym badaniu, bo nie traktuję Le Chat Pro jako poważnego narzędzia AI, z którego ktokolwiek mógłby korzystać profesjonalnie lub w ogóle go używać. Zakończyło się otrzymaniem pliku PDF ze standardowym dla LLM-ów podsumowaniem systemu Helpful Content aktualizacji, w którym wskazane zostało zaledwie 14 źródeł, głównie o charakterze informacyjnym, ale na AI slop stanowiący podstawę fundamentalnych wniosków także znalazło się miejsce:

Wyniki z Perplexity były niemal identyczne
Ktoś mógłby zapytać, czy bardziej wyspecjalizowany system w tym nie pomoże, ale w uchodzącym za gwiazdę researchu Perplexity Pro mamy do czynienia z dokładnie tym samym:
Już mi się nawet nie chciało tego klasyfikować i obliczać…
62 teksty o December Core Update 2025, a 35% to AI Slop
Co istotne, w żaden sposób nie pomagała prośba o ograniczenie się do realnych analiz („Ogranicz to do 5 najbardziej rzetelnych podsumowań efektów i wyników update’u, które nie informują o samym jego wystąpieniu (to wiem, w końcu gdyby nie zaczął się i nie zakończył, to bym nie pytał), tylko o realnych rezultatach wdrożenia Core Update December 2025″). Jeżeli już, to tylko pogarszało sprawę:
- ChatGPT wypisał dane z 3 wygenerowanych i nierzetelnych analiz, po czym z olbrzymią pewnością siebie je uprawdopodabniał.
- Dokładnie to samo zrobił Claude, tyle że na 3 zupełnie innych przykładach.
- Gemini zrobił to tylko z dwoma, ale jest to identycznie problematyczne.
Ostateczne dane prezentują się zatem następująco:
| Kategoria | Google/AIO | Gemini | ChatGPT | Claude |
|---|---|---|---|---|
| AI slop najgorszego sortu | 29% | 22% | 28% | 26% |
| Not much, ale bez dziadostwa | 19% | 3% | 6% | 3% |
| Oficjalne źródła | 0% | 9% | 0% | 8% |
| Uczciwy content informacyjny | 52% | 56% | 61% | 50% |
| Głębokie podsumowanie aktualizacji | 0% | 9% | 6% | 13% |
Natomiast jeżeli bralibyśmy pod uwagę unikalne źródła, usunęli te kompletnie niezwiązane z grudniowym Core Update i nie dzielili na narzędzia (co posłużyło mi do sformułowania wyniku z powyższego nagłówka H2, zawartego także w H1), wówczas pozostałyby 62 unikalne linki z następującą klasyfikacją:
| Kategoria | Liczba | Odsetek |
|---|---|---|
| AI slop najgorszego sortu | 22 | 35% |
| Not much, ale bez dziadostwa | 4 | 6% |
| Oficjalne źródła | 2 | 3% |
| Uczciwy content informacyjny | 29 | 47% |
| Głębokie podsumowanie aktualizacji | 5 | 8% |
Listę znajdziecie w tym arkuszu Google Spreadsheets, jeżeli chcielibyście to zweryfikować lub podważyć poszczególne klasyfikacje (co zapewne w pojedynczych przypadkach granicznych jak najbardziej ma sens, a przy tak niewielkiej próbce mocno wpływa na procenty).
Wnioski z badania
Rzeczywistość wyłaniająca się z tych danych jest następująca: Google oraz narzędzia AI w większości pokazują uczciwy content informacyjny. Problem tkwi jednak w tym, że w żadnym wypadku nie wpisywałem fraz czy zapytań związanych z samą informacją o wystąpieniu grudniowej aktualizacji. Przecież wiadomo, że takowa nastąpiła. Jasno dawałem do zrozumienia, że interesują mnie podsumowania, a w ewentualnych uściśleniach pisałem o rzetelności (Claude zaś sobie to uściślił sam).
Wniosek drugi jest więc taki, że głównym problemem określić trzeba wykorzystywanie do fundamentalnego wnioskowania materiałów, które dają dokładnie takie odpowiedzi, jakich systemy AI oczekują. Nie przeszkadza LLM-om fakt, że są oparte na fałszywych przesłankach lub generatywnym rozdmuchaniu generycznych wniosków. W sumie zdecydowanie nie może to dziwić z technicznego punktu widzenia. Nie widzę w tym problemu z samymi dużymi modelami językowymi, tylko z bazą źródeł do przetwarzania.
Powyższe wnioski prowadzą też do szerszej konkluzji: narzędzia AI nawet w trybie Deep Research zdecydowanie nie rozwiązują problemu z poszukiwaniem informacji wykraczających poza pewien poziom ogólności i konsensusowości, który w ostatnich latach sygnalizowany był coraz częściej przez użytkowników Google’a. Co więcej, udzielane przez nie odpowiedzi wykładają się właśnie tam, gdzie o rzetelność najbardziej chodzi. Jest to ponadto problem systemowy: mimo pewnych różnic pod względem dobieranych źródeł, ogółem wszystkie tryby badania głębokiego wykazywały identyczne schematy.
A wniosek końcowy i finalny? Opieranie odpowiedzi na klarownych przykładach AI slopu jasno wykazuje na potrzebę opracowania skutecznych filtrów antyspamowych, których na chwilę obecną na rynku zwyczajnie nie ma. Nie radzi sobie z tym Google, nie radzą sobie z tym LLM-y, a wydaje mi się, że znacząca część odbiorców profesjonalnego contentu w internecie nie widzi nawet takiej potrzeby.
Te artykuły powinny Cię zainteresować
- AI Slop w SEO: proces, indeksacja, wyniki z GSC [CASE STUDY]
- Badanie korelacji cech contentu z widocznością w AI Search
- ChatGPT jak Google Maps. Local Knowledge Panel jest całkiem wygodny
- Czynniki techniczne w AI Search – badanie korelacyjne
- Ćwierć miliarada dolarów w narzędziach do monitoringu AI Search
O autorze
Nazywam się Michał Małysa i od wielu lat zajmuję się zawodowo SEO oraz analizą treści, a od 2023 roku w zakres moich obowiązków i zainteresowań dość naturalnie weszło AI. Na stronie MałySEO porządkuję wiedzę o pozycjonowaniu stron internetowych, AI Search oraz działaniu LLM-ów. Prowadzę również MałySEO Newsletter, do którego subskrypcji serdecznie Cię zachęcam na podstronie najlepszego w Polsce newslettera SEO.
Jako że przygotowanie materiałów do MałySEO Newslettera oraz na bloga zajmuje nieco czasu, może zaświtać Ci w głowie dość miły z mojej perspektywy pomysł drobnego rewanżu. Jeżeli uznasz, że lektura tego wpisu była dla Ciebie czymś więcej, niż tylko szybkim odklepaniem randomowej internetowej treści, możesz postawić mi kawkę na buycoffee.to. Z góry dziękuję!

Jeżeli z jakiegoś powodu potrzebujesz się ze mną skontaktować, wyślij mail na adres kontakt[at]michalmalysa.pl